 Web site notes
Web site notes
Here I describe some of the design features, thought processes, conventions, and miscellaneous notes regarding this website (Project Nayuki). Although these facts are not expected to be directly useful to a reader, they are provided for reference and can help a reader understand how this site works.
Content and language
- Errata policy
-
I strive for perfection in my work. I accept corrections about any detail, no matter how minor it is. This site is not intended to be a blog where the posts are mere news items – I write my pages with the aim of publishing timeless reference material. Therefore I welcome any feedback to improve the quality of my text and code, even if it’s to fix a single word or punctuation mark. (Of course, bigger improvements are welcome too. All suggestions need to be justified; they need to be factually correct and I need to agree with them before I can make the edit.)
I stand behind all of my published work, and want to avoid being blamed for mistakes that cause harm, such as incorrect code or incorrect facts. A small error can have disproportionately large consequences – for example a typo in English text can leave a reader confused, and a single-character error can invalidate a math formula or destroy a working program.
- Mobile-ready page design
-
The site is designed to be decently readable on devices with narrow and small screens, namely tablets and smartphones. However, the best reading experience is still on a large desktop or laptop monitor, as there are some wide tables and code snippets that are hard to adapt for small screens.
- Print-ready page style
-
Every page on the site can be printed immediately. There is no link to a separate “print version” page, because each page has a built-in print stylesheet already. The stylesheet was consciously designed, with these major differences from the screen style: Screen uses sans-serif fonts while print uses serif; print hides boilerplate navigational elements, the right sidebar, and related links.
- HiDPI/
Retina-ready page design -
All pages have been designed and tested to display nicely on high-DPI devices (e.g. Apple laptops/
tablets/ phones with Retina displays, Android phones/ tablets, and PCs). In particular, nearly all raster images have extra resolution headroom. - American English language
-
Although I am Canadian, I find Canadian spelling to be weird for the purpose of international communication. In particular, the spelling and vocabulary are a strange blend of British and American English, leaning mostly (about 80%) towards American. But having not grown up in British culture, I definitely cannot imitate the writing style convincingly. Hence, my closest choice is to use American English. Examples of differences:
- American: color, center, organize, elevator, truck, gasoline
- Canadian: colour, centre, organize, elevator, truck, gasoline
- British: colour, centre, organise, lift, lorry, petrol
However, contrary to American/
Canadian style, I use logical quotation marks because of my background as a programmer. - Proper Unicode symbols
-
Care was taken to use Unicode symbols like {’ “ ” − × → ≤} instead of lazy ASCII symbols like {' " " - x --> <=}.
- Binary prefixes
-
1 KB means exactly 1000 bytes, and 1 KiB means exactly 1024 bytes. (The same goes for MB/MiB, GB/GiB, etc.) This respects the definitions of typical SI prefixes as well as the binary prefixes (as specified in IEC 60027-2 Amendment 2, ISO/IEC 80000-13:2008, and IEEE 1541-2002).
- Basic graphic design
-
The fanciness of the page design is kept to a minimum because I don’t consider myself a graphic designer. Thus I write CSS rules only to achieve readability and basic visual layouts, but don’t go much beyond that. The current visual theme is designed by Tyler Freedman and coded by me.
- Flexible-width layout
-
The amount of text displayed increases as the browser window width is increased, though only up to a certain point in order to limit the number of words per line. The width limit is based on em’s, not pixels. Furthermore, the design has logic to give some consideration to small screens (~800×600) and large screens (above ~1600×1200).
- Scalable vector graphics
-
There are many SVG images deployed on pages, which fits the goal of supporting HiDPI screens. I authored nearly all diagrams in LibreOffice Draw and exported these native vector drawings to SVG files. Some SVGs were lovingly hand-coded from scratch (e.g. graphs of mathematical functions), without the use of a WYSIWYG graphical editor program. A couple of SVGs are logos and icons borrowed from other sources.
The site itself
- Custom content management system
-
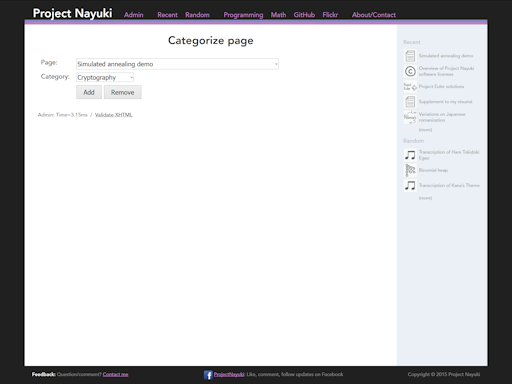
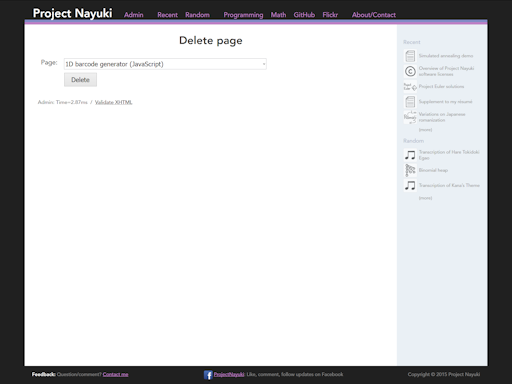
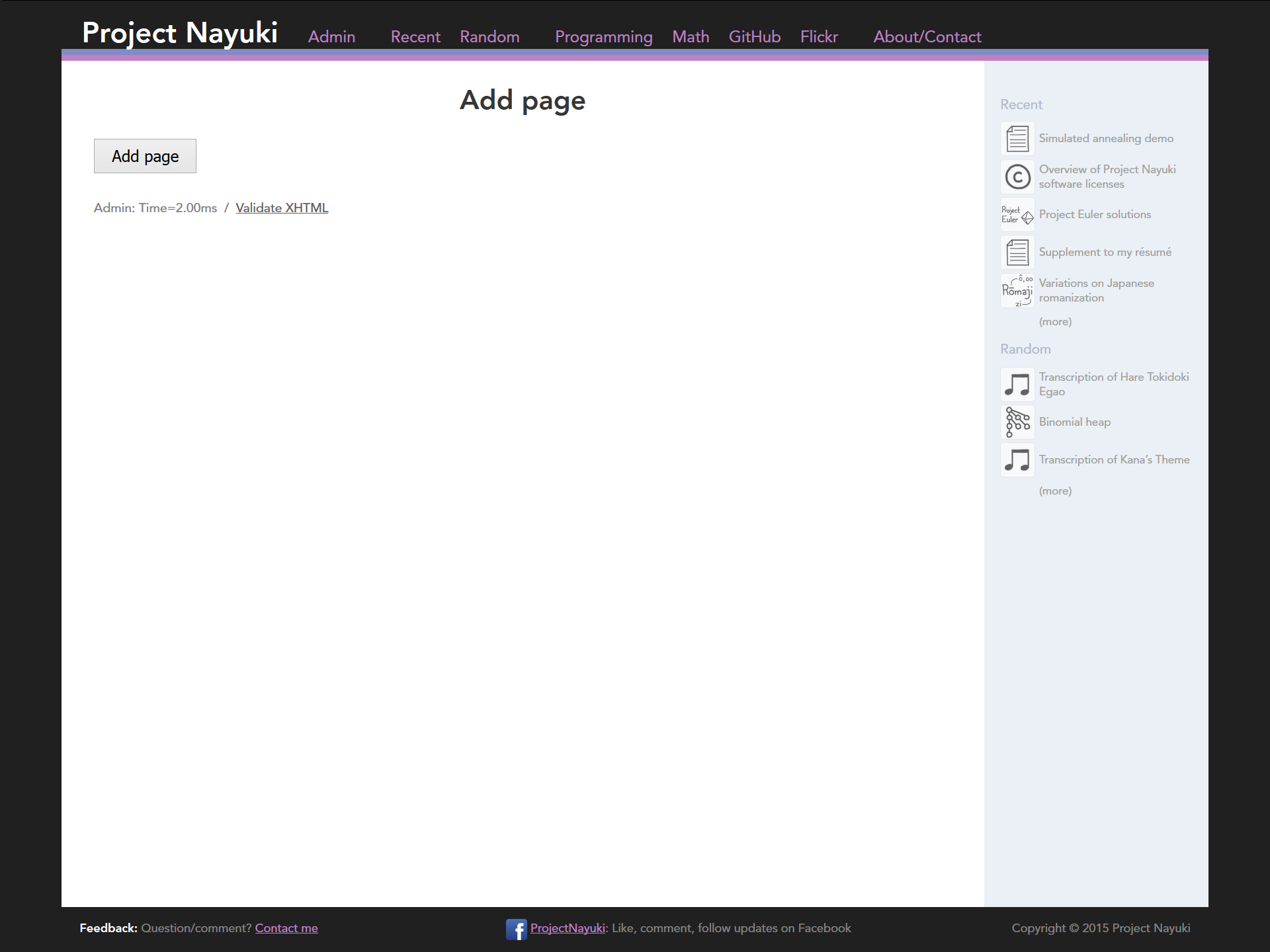
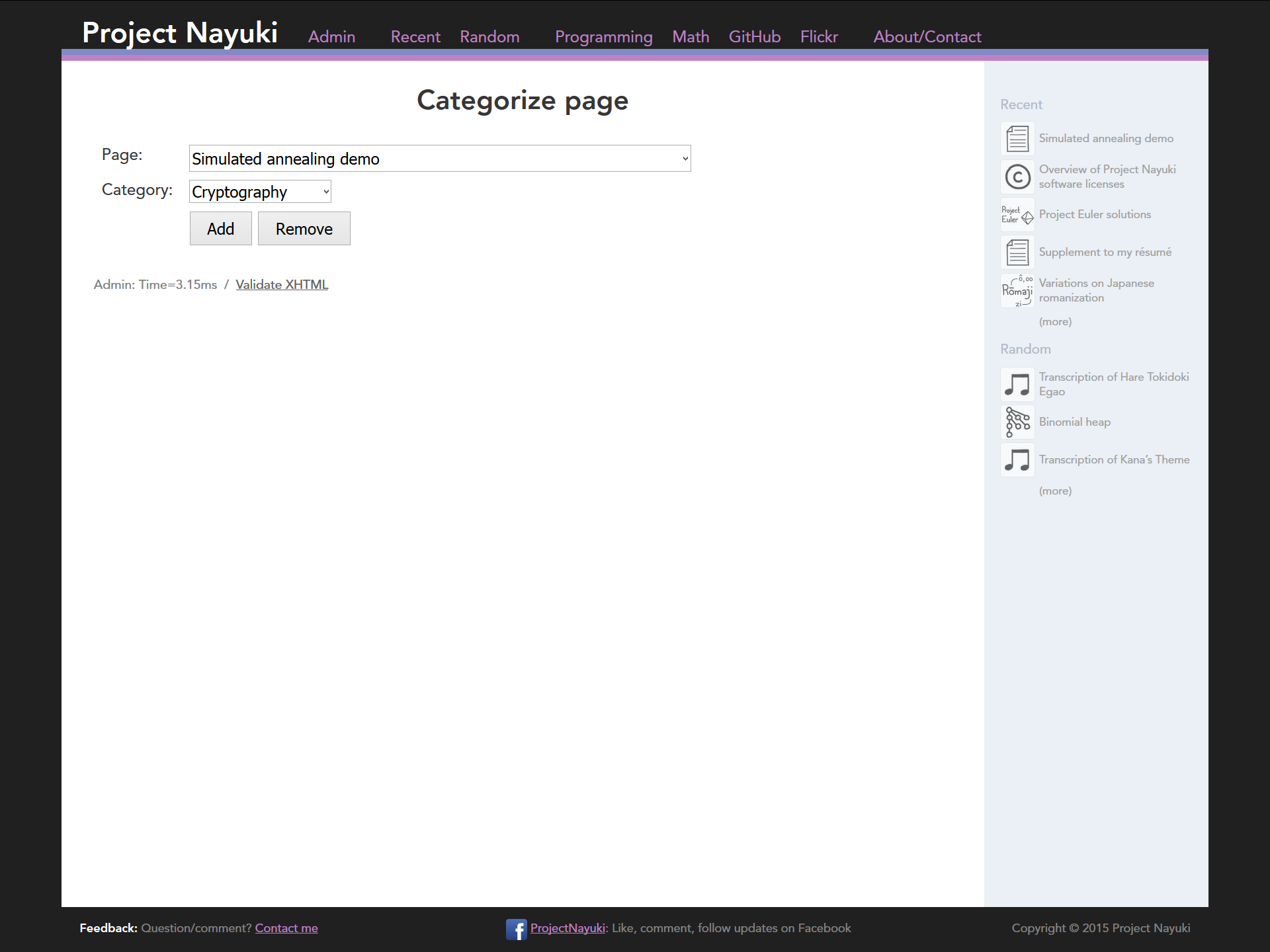
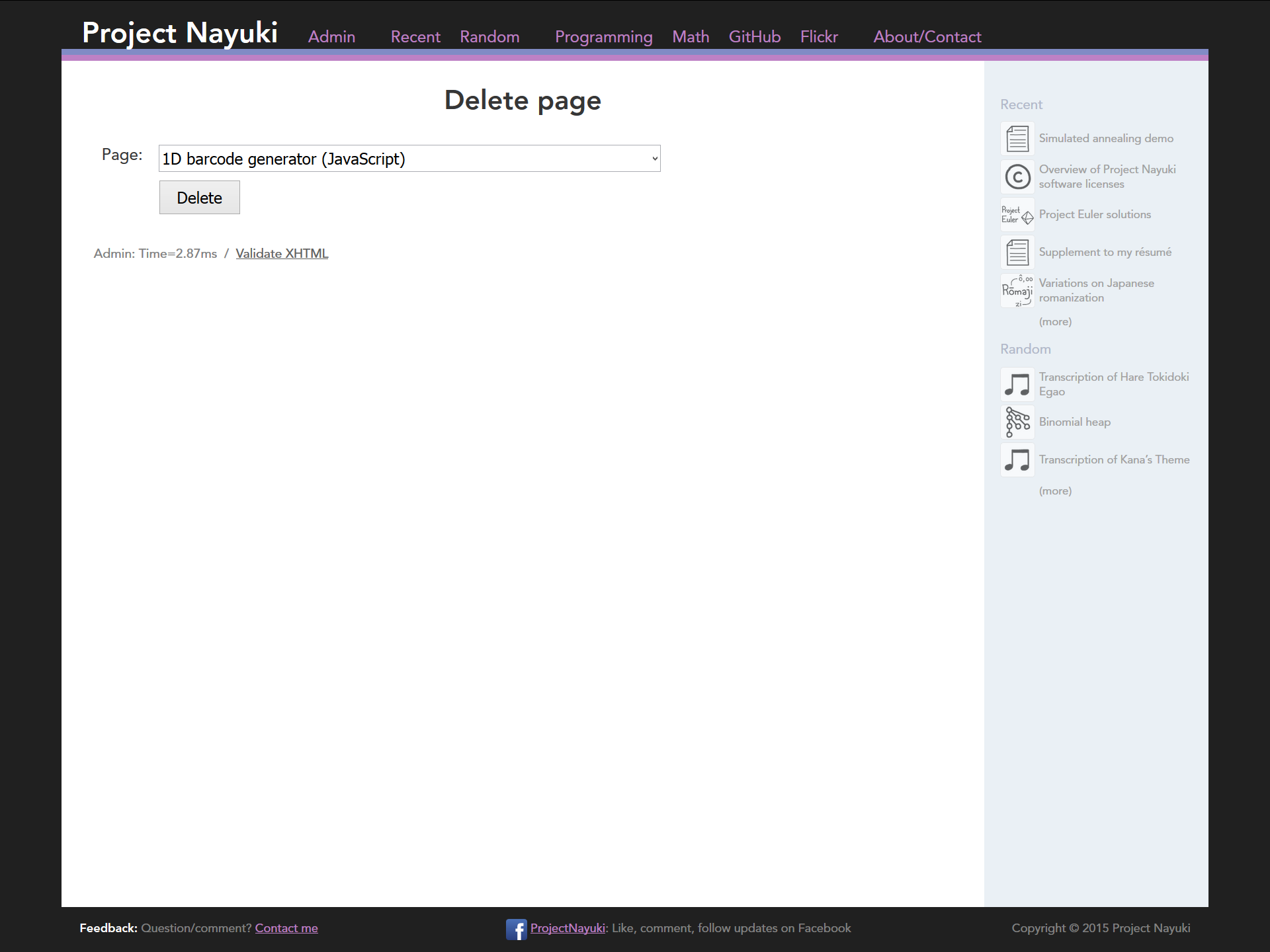
I built a custom CMS from scratch for this site. It supports adding, editing, deleting, and categorizing pages (see screenshots below). It is by no means fully featured, since it lacks features like creating/
editing/ deleting categories through the web interface. But the amount of code to implement it is fairly small, hence it remains manageable and hackable as needed. For example, at one time the web interface didn’t support deleting articles, requiring it to be done on the SQLite command line. Incidentally, all the database query code is hand-written raw SQL with no object-relational mappers.
I could have used an off-the-shelf CMS like WordPress or various niche ones. But I expect that the time it would have taken to configure the site, themes, plugins, URL routing, logging, disabling features, etc. would be comparable to just designing a CMS from scratch. Not to mention that the most popular CMSes are actively exploited, requiring continual security updates and constantly facing a risk of loss of data and service.
- Hand-coded HTML, CSS, JavaScript
-
All the HTML, CSS, and JavaScript code on this site was hand-coded in a plain text editor (not in a design tool like Dreamweaver). My design needs are not complicated, so it would be little benefit to use any framework for page layout / page rendering / styles / JavaScript functions, but they would come with a file size cost and a risk of unexpected behavior.
It’s true that hand-writing HTML code for each page takes more effort compared to WYSIWYG editing (as provided by most CMSes). Before I explain the benefits, I should note that I minimize this pain as much as possible by drafting my articles in a WYSIWYG editor like Windows WordPad (so I don’t have to see markup code or deal with HTML concepts) in a natural proportional font. When I finish writing, editing, and proofreading, I transfer the text to a plain text editor (which always uses a monospace font) and add all the HTML tags (which takes some time but little mental effort).
My justification for writing raw HTML code is that many WYSIWYG HTML editors end up being harder to use. For example in a WYSIWYG editor, adding hyperlinks and images to a page require numerous clicks and dialog boxes, especially if element attributes such as title, ID, class, CSS style, etc. need to be specified. Another example is that popular editors have little to no support for less well-known HTML elements like
<var>,<dl>,<ins>, etc., which I use on my pages fairly often. And finally, when I write raw HTML code, I have complete control over every detail, which spares me from editor glitches like extraneous paragraphs and line breaks, wrong formatting or indentation, wrong nesting, accidentally introduced invisible elements, etc. - Git version control
-
All the content hosted on the server – text, images, and code – is stored in a Git repository. This makes it easy to back up the contents of the site in multiple storage locations, audit past changes, and try experimental changes with an easy undo.
Note that the page texts are stored in a binary database file (about 1 MB large) for easy querying – not stored in plain text files. Git’s delta compression handles it just fine (adding some kilobytes for each database snapshot), but generating page diffs between versions does require more effort this way.
- Repositories of published code
-
On some of my pages, the project codebase has its own repository available on GitHub (and a few mirrored on GitLab).
Otherwise, loose code on all other pages are published in one unified repository (with full history):
 https://github.com/
https://github.com/nayuki/ Nayuki-web-published-code - Python web server
-
The site is served by a Python web server running a custom app coded in Python. I’m not too partial to using Python; other languages I would be willing to use on the server side are Java (high integrity and high performance) or Ruby (similar ease of use as Python). However, these languages are unacceptable for my needs: PHP (ugly, hostile, and dangerous), JavaScript (I make too many mistakes; poor type checking), ASP.NET (JavaScript madness, Microsoft platform), VB.NET (ugly syntax, Microsoft platform), C# (needlessly more difficult than Java, Microsoft platform). And I have no opinion on these hipster languages for web development: Scala, Clojure, Haskell.
- Major technical events
-
This website has been operating continuously since . Here is some of the technical history behind the scenes:
: Began operating at nayuki.eigenstate.org. Served by an Apache web server, the articles were static HTML files generated by a custom templating program.
: Redesigned the visual style, human navigation structure, and URL organization structure. Changed the backend to use mod_python and serve page text by querying from a database. Also added a CMS for editing and managing pages.
: Changed web server to nginx and use a Python-based web framework. Kept the URL structure and outward appearance of pages exactly the same, so visitors would notice no change at all.
: Moved the domain name to www.nayuki.io. The old domain will redirect to the new one for many years to come, so that existing links remain valid.
: Temporarily changed the visual style to mimic Hacker News for April Fools’ Day.
: Overhauled the visual style from the white-blue-gray color scheme to white-black-periwinkle-mauve, and tweaked the layout of content boxes. The base design was provided by Tyler Freedman.
: Transitioned from HTTP to HTTPS (SSL/TLS) for the entire site. All old HTTP links will redirect to the HTTPS version.
: Changed my contact email address from nayuki deleteThisWord AT eigenstate DOT removeWord org to me deleteThisWord AT nayuki DOT removeWord io. The old email address was created in May shortly after the site was launched.
: Temporarily changed the visual style to again mimic Hacker News for April Fools’ Day.
: Switched the TLS certificate provider to Let’s Encrypt.
: Configured the web server to add support for IPv6. The website was served over IPv4 since the beginning, and IPv4 will continue to be supported.
: Enabled TLS 1.3, thus speeding up connections and improving information security.
: Updated my hand-written JavaScript code from ES5 to ES6/2015 to improve readability, enabled by dropping support for Microsoft Internet Explorer 11.
Note that when individual pages or files are moved/
renamed, HTTP redirects are set up to point to the most current location of the resource. I heed the advice in the article “Cool URIs don’t change” by Tim Berners-Lee. - Page dates and history
-
Each page (article) indicates the date it was last updated. The date a page was first published is not indicated because it might confuse readers. I don’t reset the datestamp when making small changes like such as tweaking a few words. All pages have full edit history available in the website’s private repository, but I don’t believe making it available publicly is useful.

Programming and code
- Semantic use of HTML
-
The HTML code is designed to strictly obey semantic usage of elements. This means avoiding practices such as using
<table>for presentation layout, adding meaningless whitespace and line breaks, using font styles to simulate headings, using numbers/symbols to simulate ordered/ unordered lists, etc. This also means judiciously embracing HTML constructs like <em>,<code>,<dl>,<thead>,<th>,<var>,<abbr>,<nav>, etc.This result of this semantic HTML markup can be seen by either disabling CSS in the browser (e.g. in Mozilla Firefox: Menu bar → View → Page Style → No Style) or by using a text-only browser like Links or Lynx. You will notice that the page is quite readable, proper headings exist for each section, and there are no stray layout tables or images or irrelevant text.
- Usage of XHTML5
-
All the web pages transmitted are valid XHTML5 code (with an exception for pages that require JavaScript
document.write()). In other words, they are HTML5 documents serialized in XML syntax.This takes more effort upfront than using plain HTML because the syntax is stricter and it requires setting the media type as application/
xhtml+xml on the web server, however I find the benefits to be well worth it. The strict XML parser makes it easy to detect common errors like unclosed tags, improper nesting, improper character entities, and miscellaneous nonsense syntax. And because of this strictness, I do not encounter weird, hard-to-debug issues with CSS rules or JavaScript DOM manipulation caused by a misunderstanding of how a malformed HTML page was silently corrected (such as improperly nested <div>elements for page layout). - MathJax for math typesetting
-
The math-intensive pages (examples) use MathJax for typesetting mathematical formulas. The syntax is pretty lightweight and essentially the same as LaTeX, and the JavaScript library is easy to deploy. Other pages that have only simple math would skip this and just use HTML constructs like
<var>and<sup>. - Programming code style
-
I try to maintain a tightly consistent code style in all my code, right down to individual characters and spaces. For the most part I have been successful, and accidental style deviations are very rare.
I choose to use tabs for indentation because they are more semantic and avoids the redundancy of having multiple spaces. I do indent blank lines for consistency.
For brace-based languages (Java, C/C++, C#, POV-Ray, etc.) I use the “one true brace style” (1TBS/OTBS) by personal preference (which incidentally is the community default style in Java). I like the compactness of putting the opening brace on the same line as the condition; moreover I nearly always omit braces for one-line statements. Example:
void f() { if (a == b) { foo(); bar(); } else { qux(); baz(); } }I maintain correct indentation and formatting as I write code, not after the fact. I don’t use automatic formatters – in fact, running my code through a formatter would wreck the style and make it less consistent.
My code style is discussed at length on its own page.