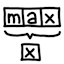 Sliding window minimum/maximum algorithm
Sliding window minimum/maximum algorithm

Introduction
Suppose we have an array A containing n numbers, and want to compute the minimum or maximum of each possible consecutive k elements. Perhaps we want to apply a maximum filter to an image, or examine how many substrings’ maxima meet a certain criterion. The problem comes up in some programming challenge problems.
The naive brute-force approach is to write two nested for-loops, running in Θ(nk) time (Java code):
int[] maxs = new int[A.length - k + 1];
for (int i = 0; i < maxs.length; i++) {
int temp = A[i];
for (int j = 1; j < k; j++) {
// Can flip inequality to get minimum
if (A[i + j] > temp)
temp = A[i + j];
}
maxs[i] = temp;
}
To speed things up, it is also possible to precompute a table of maxima of certain ranges. But that would be slower and more complicated than the algorithm described below.
Deque-based algorithm
The best approach uses a deque (double-ended queue) in a clever way, and runs in Θ(n) time using Θ(k) space. The rest of this discussion assumes a maximization problem, but all the ideas are equally applicable to minimization too. The key insight is that the deque always maintains a list of candidate maxima in monotonically decreasing order.
Trivial scenarios
Consider this ascending example (Python code):
A = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9] k = 4 max(A[0 : 4]) -> 3 max(A[1 : 5]) -> 4 max(A[2 : 6]) -> 5 (... et cetera ...) max(A[6 : 10]) -> 9
When we work on the array from left to right, every new element we see is always bigger than all previous elements seen. Furthermore, the new element “expires” later than all previous elements. These two facts combined mean that we can forget about all previous smaller elements as soon as we see a bigger one.
Now consider this descending example (Python code):
A = [9, 8, 7, 6, 5, 4, 3, 2, 1, 0] k = 4 max(A[0 : 4]) -> 9 max(A[1 : 5]) -> 8 max(A[2 : 6]) -> 7 (... et cetera ...) max(A[6 : 10]) -> 3
When we work on this array from left to right, the new element is smaller than the previous elements. After we process the substring [9, 8, 7, 6], the 9 on the left needs to be removed, and 5 needs to be added to the right.
Reasoning process
Thinking carefully about those two scenarios, we can come up with these rules for the deque:
The deque shall always represent some kind of processing on a particular range of consecutive array elements, e.g.
A[i : j](Python notation).When we increment the array range’s right endpoint (
j) to add a new element, we manipulate the tail of the deque. Suppose the new element’s value isx. Looping while the deque is non-empty and its tail element is less thanx, we remove the tail element. This is becausexwill be removed later than those elements andxis strictly larger, so those other elements will never be a range maximum from now on. Finally, addxto the tail of the deque.When we increment the array range’s left endpoint (
i) to remove a previously added element, we manipulate the head of the deque. Suppose the just-removed element’s value isx. If the deque’s head element equalsx, then remove the head element. This is becausexis no longer in the array range, so it cannot be in the deque either. Otherwise the deque’s head element must be greater thanx, which means the valuexwas already removed from the deque at some point in the past. The head of the queue cannot possibly be less thanx.
The rules above imply the following properties for our deque:
The deque is empty if and only if the array range is empty.
Whenever the deque is non-empty, its head element is the maximum of the current array range.
When viewed from head to tail, the deque is always a subsequence (and subset) of its corresponding array range.
When viewed from head to tail, the deque is a non-increasing (monotonically decreasing) sequence of numbers.
Adding an element and updating the deque takes worst-case Θ(k) time but amortized Θ(1) time.
Removing an element and updating the deque takes worst-case Θ(1) time.
The deque can contain duplicate elements. In fact, it must keep track of the number of copies so that element removal will update the maximum at the correct time.
The left and right endpoints can move almost independently, i.e. the length of the array range can grow and shrink, not just stay at some fixed value k. Of course, the left endpoint index must always be less than or equal to the right endpoint index for the range to make sense.
The sequence of elements removed from the left endpoint is always a prefix of the sequence of elements added to the right endpoint. In other words, removal must happen in the same order as addition (although it is possible to postpone removal indefinitely).
Finally, we can take these rules and properties and state the data structure semi-formally in terms of invariants:
At all times, the deque (when viewed from head to tail) is a subsequence of the array range
A[i : j]. For each indexmsatisfyingi <= m < j, the elementA[m]is present in the deque if and only if the valueA[m]is at least as large as every value after indexm. This definition implies that the deque is a non-increasing sequence of values.The operation to increment the right endpoint
jwill preserve the data structure’s invariant. Assume the invariant holds before the operation, and let the new value bex. The operation removes all tail values beforexthat are less thanx, because those values are no longer eligible to be in the deque as per the definition. Because the deque is non-increasing, we can stop when we reach a value that is equal to or greater thanx. Then,xis added to the tail of the deque becausexis trivially at least as large as any elements after it (which there are none).The operation to increment the left endpoint
iwill preserve the data structure’s invariant. Assume the invariant holds before the operation, and let the value to be removed bex. If the head element of the deque equalsxand came from the same index, then it gets removed and we’re good. If the head element has the same value asxbut came from a later index, that is impossible because by definitionA[i] = xwould also be present in the deque and be in front of this duplicate value. Otherwise if the head element doesn’t equalx, then it must not be removed.
Source code 
Library and test suite
- Java (SE 7+)
- Python
- C++ (C++11 and above)
- Rust
Min/max image filter
Java program: MinMaxImageFilter.java
Usage: java MinMaxImageFilter InImg.(bmp|png) (min|max) (box|disc) Radius OutImg.png
Example: java MinMaxImageFilter input.bmp max disc 8.6 output.png
This program uses the sliding window algorithm to compute a minimum or maximum filter on a color image. First, a copy of the image is made and converted to grayscale. Next, each intermediate pixel is set to the value of the minimum/
Example image and filtered results:
Box minimum, radius 4, Photoshop
Box minimum, radius 4, Nayuki
Disc minimum, radius 4.2, Nayuki
Box maximum, radius 12, Photoshop
Box maximum, radius 12, Nayuki
Disc maximum, radius 12.3, Nayuki
Example image, original, unfiltered
Notes:
For the box filter, the radius is effectively rounded down to the nearest integer; e.g. a radius of 7.5 behaves the same as a radius of 7.
For the disc filter, the result is slightly ugly if the radius is exactly an integer or a tiny bit above it; e.g. a radius of 4.0 to 4.1 produces more jaggies than normally expected from a disc.
Let w be the width of the image, h be the height of the image, and r be the radius of the filter. The running time of the program is Θ(wh) for the box filter (independent of radius) and Θ(whr) for the disc filter. Note that the box filter is separable into two 1D filters. Without the sliding window algorithm, the naive box filter (separable) runs in Θ(whr) time and the naive disc filter runs in Θ(whr2) time, both of which are slower by a factor of r.
Mainstream image editors like Adobe Photoshop have min/max filters, which is where my inspiration comes from. When the image is filtered in Photoshop, the overall shape looks the same as my filter. However, Photoshop only supports box filtering, which yields ugly results for tasks like outlining text. Also, Photoshop performs filtering on each channel independently, whereas my program compares based on grayscale value and outputs the associated color value. This means that Photoshop’s min/max filters may fabricate colors not present in the original image, whereas my program never creates new colors. Adobe Photoshop CS2 was the version tested. Also Corel Photo-Paint 8 was tested, and it behaved similarly (only box kernel supported, channels filtered independently) but not identically.