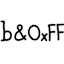 Java’s signed byte type is a mistake
Java’s signed byte type is a mistake
The Java programming language has a signed byte type but not an unsigned one. I regard this design to be a terrible mistake and that the reverse situation would make more sense. Based on a range of applications, I find that the unsigned byte type has far more use cases and is easier to work with than the signed byte type.
Bit packing
In Java, it is not uncommon to manually convert an int (signed 32-bit integer) to and from an array of four bytes. When packing signed bytes into an int, each byte needs to be masked off because it is sign-extended to 32 bits (rather than zero-extended) due to the arithmetic promotion rule.
Consider the example of packing an array b of 4 bytes to an int x in big-endian, and compare the amount of code when the byte type is signed (actual) versus unsigned (hypothetical):
// Signed bytes, clear code
int x = ((b[0] & 0xFF) << 24) | ((b[1] & 0xFF) << 16) |
((b[2] & 0xFF) << 8) | ((b[3] & 0xFF) << 0);
// Signed bytes, minimal parentheses
int x = b[0] << 24 | (b[1] & 0xFF) << 16 |
(b[2] & 0xFF) << 8 | b[3] & 0xFF;
// Unsigned bytes, clear code
int x = (b[0] << 24) | (b[1] << 16) | (b[2] << 8) | (b[3] << 0);
// Unsigned bytes, minimal parentheses
int x = b[0] << 24 | b[1] << 16 | b[2] << 8 | b[3];
As we can see, if the byte type were unsigned then the bit-packing code is significantly shorter, has fewer operations, and is clearer.
Byte constants
When reading or writing file formats, or when implementing cryptographic algorithms, sometimes you need to declare a byte constant or a byte array constant. Often some of these values are greater than 127, which exceed the signed range. So you would either need to declare the constant normally and downcast it (verbose), or convert the constant to its signed interpretation and declare that in the code (hurts readability). Examples:
byte[] b = {0xFF, ...}; // Compile-time error
byte[] b = {(byte)0xFF, ...}; // OK, but ugly
byte[] b = {-1, ...}; // Obscures its unsigned value
byte[] b = intsToBytes(new int[]{0xFF, ...}); // Baroque[0]
When comparing a byte value to an int value, the byte is sign-extended to an int and then this value is compared to the other int. One likely mistake[1] is to test whether a byte value equals an unsigned int constant in a way that is always false (for example in file format parsing):
byte[] b = (...); // e.g. read file data // b[0] is in the range [-128,127], thus never equal to 255 if (b[0] == 0xFF) ... // Silent programming error
Applications
In practice, unsigned bytes are used as a native storage type for many things: 8-bit color channels in typical 24-bit RGB images, 8-bit extended ASCII characters (but that’s obsolete thanks to UTF-8), opcodes for microprocessors. In contrast, I can only think of one real application for signed bytes: uncompressed PCM audio samples. But 8-bit audio sounds bad, so nobody prefers to use it anyway.
Final thoughts
As an aside, the C programming language has signed and unsigned versions of every integer type that is supported by the language. But this opens up a whole different can of worms, like implicit up-conversions, comparing signed and unsigned values, mixed-type arithmetic, unsigned dominating over signed, and more. Add to fact that the integer types have implementation-dependent (i.e. compiler- and platform-dependent) bit widths, and that is why I hesitate to write code in C that involves absolutely precise and correct reasoning about value ranges, overflow, exact storage requirements, etc.
For the sake of completeness, I should mention that I have no problems with short, int, and long being signed types. It’s just byte that irritates me. But in light of this, we can see that having byte as a signed type preserves the consistency[2] of having signed integer types in Java – though not enough to justify its poor practical usage.
So there you have it, these are the reasons for why I believe Java’s signed byte type is a mistake and should have been designed as an unsigned byte type instead.
Notes
[0]: You have to implement
intsToBytes()yourself; there is no existing library function to do this for you. I consider this workaround baroque, but I used this alternative a few times in my cryptography library because in those cases for large arrays, it was the least of all evils.[1]: This mistake was illustrated in the book Java Puzzlers, chapter 3 “A Big Delight in Every Byte”.
[2]: But the
chartype is an oddball, being a 16-bit unsigned integer type. In practice, though, doing arithmetic onchars is rare.