 GIF optimizer (Java)
GIF optimizer (Java)
Introduction
The GIF image file format uses Lempel–Ziv–Welch (LZW) compression to encode the pixel data. While there is only one correct way to decompress a given piece of LZW data, there are many valid ways to compress data using the LZW scheme.
One way to losslessly optimize the size of the compressed bit stream is to carefully choose when to clear the dictionary during stream processing. It appears that popular GIF encoders only clear the dictionary according to fixed rules instead of adaptively. Thus by making better choices, my encoder can produce smaller GIF files. It shows that existing encoder software have not exploited the full potential of the GIF format.
But practically speaking, PNG is far superior to GIF in compression and features (such as true color and partial transparency, but lacking animation). The work described in this page here can be considered an exercise to show that slightly more compression can be squeezed out of GIF than is typically possible. At the same time though, the general concept of choosing where to {clear the dictionary / split compression blocks} to optimize the size is applicable to many compression formats.
The optimization I implemented here is based on this key idea: After a Clear code, the way the rest of the input data is compressed does not depend on the earlier already-processed part. So CompressedLength(Data) = min {CompressedLength(Data[0 : i]) + CompressedLength(Data[i : DataLength]) | i ∈ [0, DataLength]}. The way to evaluate this formula is to apply dynamic programming, starting with short suffixes of the input data, progressively lengthening the suffix until we process the whole data array. There is a numerical example at the bottom of the page to illustrate this algorithm.
Source code 
Main programs:
- OptimizeGif.java
-
Usage:
java OptimizeGif [Options] Input.gif Output.gifThis program reads the given input GIF, losslessly optimizes all the LZW data blocks, and writes a new output GIF file. The structures, palettes, metadata, arrangement, and post-decompression pixel data are left changed. Animated GIFs are supported.
- WriteGif.java
-
Usage:
java WriteGif [Options] Input.bmp/png/gif Output.gifThis program reads the given input image and writes an output GIF file with identical pixel content. The image must have 256 or fewer unique colors. For detailed options and limitations, see the header comment in the source code.
(Note: Do not process input images that are 8-bit grayscale-paletted; please convert them to 24-bit RGB first. This is because Java’s ImageIO returns a BufferedImage which has a bug with regards to gamma correction, resulting in a washed-out output image.)
Required libraries:
- BitInputStream.java
- BitOutputStream.java
- GifLzwCompressor.java
- GifLzwDecompressor.java
- MemoizingInputStream.java
- SubblockInputStream.java
- SubblockOutputStream.java
Warning: This code is not production-level quality. It could crash at random times and/or corrupt data silently. Nayuki provides no warranty or compensation for any losses incurred.
Sample images and benchmarks
Notes:
In each set of images, every image has the same picture data when decoded to RGB888. There is no need to view each file; they are only provided to prove that the output files are decodable and the file sizes are real. All file sizes are given in bytes.
After each image there is some commentary about the content and compression. After the entire set of images, there is text discussing general observations and conclusions about all the images.
- Color photo – landscape
-
Image content: Real-life photographic content with many colors and minor dithering. (Source)

Format, method File size Bar graph BMP, 8-bit 263 222 GIF, IrfanView 184 279 GIF, Adobe Photoshop 184 282 GIF, uncompressed 298 032 GIF, Nayuki monolithic 329 326 GIF, Nayuki blocksize=1 180 912 GIF, Nayuki blocksize=2 180 928 GIF, Nayuki blocksize=4 180 940 GIF, Nayuki blocksize=8 180 956 GIF, Nayuki blocksize=16 180 998 GIF, Nayuki blocksize=32 181 038 GIF, Nayuki blocksize=64 181 095 GIF, Nayuki blocksize=128 181 170 GIF, Nayuki blocksize=256 181 234 GIF, Nayuki blocksize=512 181 371 GIF, Nayuki blocksize=1024 181 523 GIF, Nayuki blocksize=2048 181 647 GIF, Nayuki blocksize=4096 181 956 GIF, Nayuki blocksize=8192 183 116 GIF, Nayuki blocksize=16384 187 923 GIF, Nayuki blocksize=32768 214 534 GIF, Nayuki blocksize=65536 253 110 PNG, OptiPNG -o7 161 256 Discussion: Monolithic compression performs very poorly because the LZW dictionary is built from the colors in the top of the image (sky blue), but the bottom of the image has no such colors (green). Furthermore the dictionary stops growing after 4096 entries, which means multi-pixel entries with green cannot be added. So the bottom is encoded using literal symbols but with an expanded bit width, thus wasting lots of space and performing even worse than the uncompressed GIF.
- Color photo – portrait
-
Image content: Real-life photographic content with many colors and minor dithering. (Source)
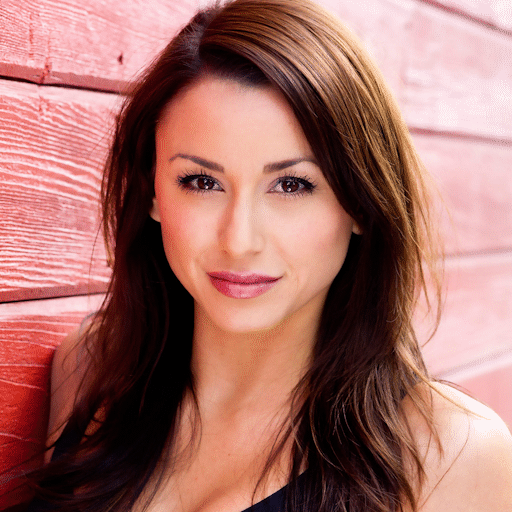
Format, method File size Bar graph BMP, 8-bit 263 222 GIF, IrfanView 191 012 GIF, Adobe Photoshop 190 918 GIF, uncompressed 298 032 GIF, Nayuki monolithic 312 528 GIF, Nayuki blocksize=1 188 018 GIF, Nayuki blocksize=2 188 038 GIF, Nayuki blocksize=4 188 057 GIF, Nayuki blocksize=8 188 084 GIF, Nayuki blocksize=16 188 138 GIF, Nayuki blocksize=32 188 165 GIF, Nayuki blocksize=64 188 218 GIF, Nayuki blocksize=128 188 257 GIF, Nayuki blocksize=256 188 402 GIF, Nayuki blocksize=512 188 590 GIF, Nayuki blocksize=1024 188 781 GIF, Nayuki blocksize=2048 189 042 GIF, Nayuki blocksize=4096 189 407 GIF, Nayuki blocksize=8192 189 804 GIF, Nayuki blocksize=16384 198 114 GIF, Nayuki blocksize=32768 220 031 GIF, Nayuki blocksize=65536 240 925 PNG, OptiPNG -o7 160 533 Discussion: Monolithic compression performs poorly here too, and the file sizes have the same pattern as the landscape photo.
- Grayscale text
-
Image content: Grayscale anti-aliased Latin-alphabet text. (Document source)

Format, method File size Bar graph BMP, 8-bit 263 222 GIF, IrfanView 59 702 GIF, Adobe Photoshop 59 735 GIF, uncompressed 298 032 GIF, Nayuki monolithic 51 544 GIF, Nayuki blocksize=1 50 645 GIF, Nayuki blocksize=2 50 645 GIF, Nayuki blocksize=4 50 684 GIF, Nayuki blocksize=8 50 713 GIF, Nayuki blocksize=16 50 726 GIF, Nayuki blocksize=32 50 726 GIF, Nayuki blocksize=64 50 793 GIF, Nayuki blocksize=128 50 793 GIF, Nayuki blocksize=256 50 808 GIF, Nayuki blocksize=512 50 808 GIF, Nayuki blocksize=1024 50 817 GIF, Nayuki blocksize=2048 50 817 GIF, Nayuki blocksize=4096 51 021 GIF, Nayuki blocksize=8192 51 021 GIF, Nayuki blocksize=16384 51 544 GIF, Nayuki blocksize=32768 51 544 GIF, Nayuki blocksize=65536 51 544 PNG, OptiPNG -o7 30 697 Discussion: This image is very compressible, as seen in the stark difference between the compressed GIF and PNG files versus the uncompressed GIF and BMP files.
- Monochrome text
-
Image content: Simple black-and-white text without smoothing. (Text sources: English, Chinese, Arabic)

Format, method File size Bar graph BMP, 8-bit 32 830 GIF, IrfanView 19 237 GIF, Adobe Photoshop 19 243 GIF, uncompressed 148 068 GIF, Nayuki monolithic 19 204 GIF, Nayuki blocksize=1 18 473 GIF, Nayuki blocksize=2 18 476 GIF, Nayuki blocksize=4 18 476 GIF, Nayuki blocksize=8 18 487 GIF, Nayuki blocksize=16 18 492 GIF, Nayuki blocksize=32 18 505 GIF, Nayuki blocksize=64 18 505 GIF, Nayuki blocksize=128 18 505 GIF, Nayuki blocksize=256 18 511 GIF, Nayuki blocksize=512 18 511 GIF, Nayuki blocksize=1024 18 511 GIF, Nayuki blocksize=2048 18 511 GIF, Nayuki blocksize=4096 18 526 GIF, Nayuki blocksize=8192 18 526 GIF, Nayuki blocksize=16384 18 526 GIF, Nayuki blocksize=32768 18 612 GIF, Nayuki blocksize=65536 18 682 PNG, OptiPNG -o7 14 826 Discussion: The uncompressed GIF is exceedingly inefficient (compared to the 8-bit case) because the encoder needs to emit a Clear code every 2 symbols; furthermore each symbol is encoded with 3 bits, not 2. The uncompressed BMP reference shows that the GIF compressed size is around 50%.
- Vertically varying noise
-
Image design: This tests whether clearing the dictionary as the colors change vertically can help compression. (Image generated by Nayuki)
Format, method File size Bar graph BMP, 8-bit 263 222 GIF, IrfanView 220 936 GIF, Adobe Photoshop 221 090 GIF, uncompressed 298 032 GIF, Nayuki monolithic 372 435 GIF, Nayuki blocksize=1 216 929 GIF, Nayuki blocksize=2 216 938 GIF, Nayuki blocksize=4 216 947 GIF, Nayuki blocksize=8 216 971 GIF, Nayuki blocksize=16 216 996 GIF, Nayuki blocksize=32 217 035 GIF, Nayuki blocksize=64 217 074 GIF, Nayuki blocksize=128 217 135 GIF, Nayuki blocksize=256 217 249 GIF, Nayuki blocksize=512 217 369 GIF, Nayuki blocksize=1024 217 511 GIF, Nayuki blocksize=2048 217 708 GIF, Nayuki blocksize=4096 218 329 GIF, Nayuki blocksize=8192 218 405 GIF, Nayuki blocksize=16384 227 260 GIF, Nayuki blocksize=32768 284 308 GIF, Nayuki blocksize=65536 338 891 PNG, OptiPNG -o7 177 536 Discussion: Because the range of colors varies vertically, it is advantageous to periodically clear the dictionary to remove patterns that contain colors absent in subsequent lines.
- Horizontally varying noise
-
Image design: This tests whether the advantage is nullified compared to the vertically varying case, because every line will cover most of the color range. (Image generated by Nayuki)

Format, method File size Bar graph BMP, 8-bit 263 222 GIF, IrfanView 322 769 GIF, Adobe Photoshop 322 810 GIF, uncompressed 298 032 GIF, Nayuki monolithic 308 301 GIF, Nayuki blocksize=1 291 816 GIF, Nayuki blocksize=2 291 818 GIF, Nayuki blocksize=4 291 825 GIF, Nayuki blocksize=8 291 834 GIF, Nayuki blocksize=16 291 852 GIF, Nayuki blocksize=32 291 873 GIF, Nayuki blocksize=64 291 938 GIF, Nayuki blocksize=128 292 040 GIF, Nayuki blocksize=256 292 183 GIF, Nayuki blocksize=512 306 535 GIF, Nayuki blocksize=1024 307 280 GIF, Nayuki blocksize=2048 307 280 GIF, Nayuki blocksize=4096 307 352 GIF, Nayuki blocksize=8192 307 352 GIF, Nayuki blocksize=16384 307 874 GIF, Nayuki blocksize=32768 308 025 GIF, Nayuki blocksize=65536 308 301 GIF, Nayuki custom tiled 216 720 PNG, OptiPNG -o7 224 173 Discussion: We see that LZW compression is very difficult to do effectively in this case. Nearly all the compressors fall apart and do worse than the dumb uncompressed encoding, except my encoder with blocksize 256 or below.
However, by splitting the image into thin vertical strips and compressing each strip independently, it is possible to circumvent the problem and achieve decent compression just like the vertically varying case. In fact it is surprising that this beats PNG compression. This tiled image was created manually using a custom program (not published). The downside is that many (but not all) GIF decoders are broken and incorrectly assume that the image is an animation where each strip is a new frame, even though the duration of each strip is supposed to be exactly zero.
- Uniform random noise
-
Image design: The worst case possible, where the expected size must be at least 262 144 bytes as dictated by information entropy. (Image generated by Nayuki)

Format, method File size Bar graph BMP, 8-bit 263 222 GIF, IrfanView 361 091 GIF, Adobe Photoshop 361 078 GIF, uncompressed 298 032 GIF, Nayuki monolithic 374 053 GIF, Nayuki blocksize=1 297 143 GIF, Nayuki blocksize=2 297 147 GIF, Nayuki blocksize=4 297 159 GIF, Nayuki blocksize=8 297 179 GIF, Nayuki blocksize=16 297 213 GIF, Nayuki blocksize=32 297 279 GIF, Nayuki blocksize=64 297 399 GIF, Nayuki blocksize=128 297 514 GIF, Nayuki blocksize=256 297 659 GIF, Nayuki blocksize=512 312 777 GIF, Nayuki blocksize=1024 327 475 GIF, Nayuki blocksize=2048 344 775 GIF, Nayuki blocksize=4096 361 891 GIF, Nayuki blocksize=8192 368 206 GIF, Nayuki blocksize=16384 371 328 GIF, Nayuki blocksize=32768 372 735 GIF, Nayuki blocksize=65536 373 532 PNG, OptiPNG -o7 262 759 Discussion: There are absolutely no patterns in the data, and the performance comes down to how badly the compression method adds overhead and how badly it uses inefficient encodings.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
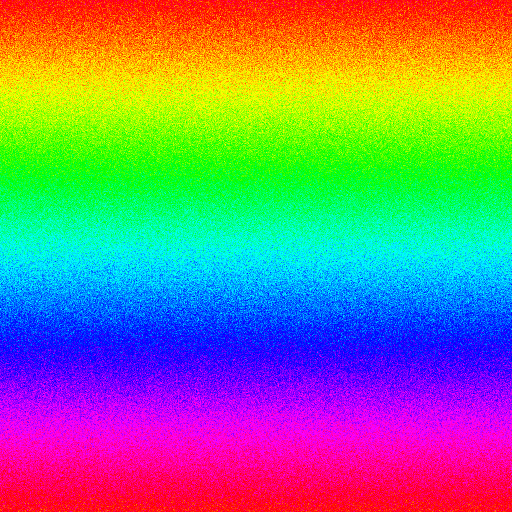{kind=link}
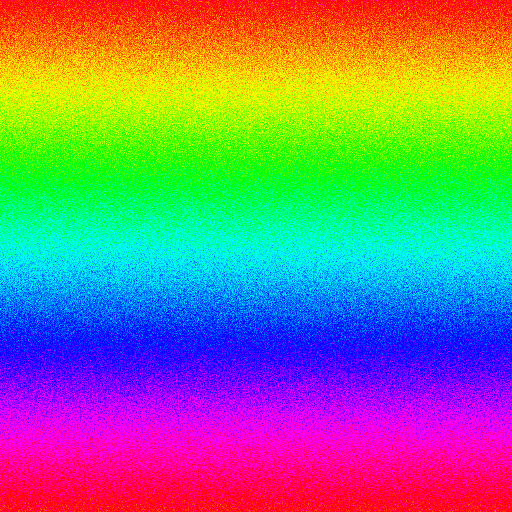{kind=link}
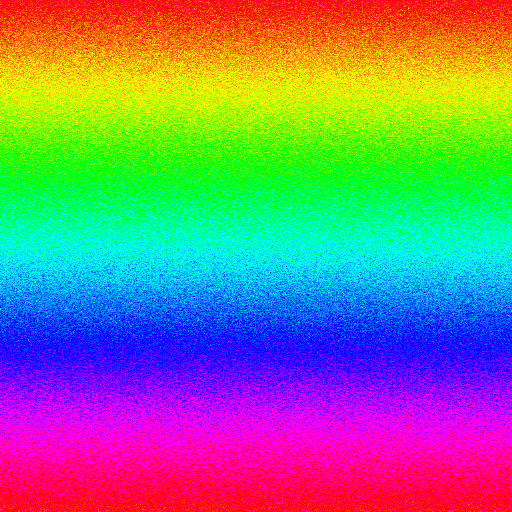{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Overall observations and notes
My GIF optimizer, when using an appropriate block size, creates files that are consistently smaller than popular GIF encoders like IrfanView and Photoshop. For real-world images (not pathological noise), the size reduction is about 1 to 2%. We can see that GIFs can indeed be optimized, but it is a matter of opinion whether the gain is worth the hassle or not.
The uncompressed GIF and uncompressed BMP file sizes only depend on the bit depth (from 1 to 8 bits per pixel) and the total number of pixels (width × height); they don’t depend on the pixel values or scene complexity at all. For reference, the raw size of an arbitrary uncompressed bitmap image is equal to (width × height × bits per pixel / 8) bytes, excluding any headers or overhead.
Uncompressed GIF refers to the technique where only literal codes are used (never using codes for multi-symbol dictionary entries), and the dictionary is always cleared before the code width increases. Thus when two images have the same number of palette entries (e.g. 256) and same number of pixels (even if the dimensions are different, like 100×100 vs. 25×400), the uncompressed encoding of both images will have the same size.
Monolithic GIF means that the dictionary is never cleared. This is equivalent to setting blocksize ≥ width × height. The dictionary fills up based on colors and patterns on the top side of the image, and fails to adapt to the characteristics of the rest of the image.
-
The block size parameter in my encoder works as follows: For an example block size of 512, it means that there is a possibility (but not obligation) to clear the dictionary after every 512 input bytes encoded. If the image happens to have a width of 512 pixels, then this also means there is an opportunity to clear the dictionary at the start of each image row.
The asymptotic time complexity of my encoder is Θ(FileSize2 / BlockSize), and the asymptotic space complexity is Θ(FileSize / BlockSize). Hence for a given block size, doubling the file size will quadruple the running time and double the memory usage. And for a given file size, halving the block size will double both the time and memory.
The PNG files are smaller than the GIFs by a wide margin, proving the futility of using GIF as a modern format. (And we can make the PNGs a few percent even smaller with PNGZopfli, for example.)
The GIF decoders in some programs exhibit a bug with regards to the “deferred clear code”. IrfanView 4.38 and Corel Photo-Paint 8 were shown to decode some images incorrectly without warning, even when other decoders (e.g. Windows Explorer, Mozilla Firefox) produced the correct image. The standard workaround to accommodate these broken decoders is to clear the dictionary before or immediately at the point when the dictionary reaches the maximum size of 4096 entries. Both of my programs WriteGif and OptimizeGif implement this optional workaround, and is activated when you use the command-line option dictclear=4096 (or 4095). However, using this option may drastically hurt compression efficiency, and largely defeats the goal of GIF optimization because DCC is a crucial encoding tool.
IrfanView’s and Photoshop’s GIF encoders do not attempt to do any optimization or content-adaptive encoding. IrfanView clears the dictionary precisely every time it fills up, and Photoshop clears it just a few entries before filling up. So these encoders clear after every ~4000 output symbols emitted (depending on the initial bit width), which means at least ~4000 input pixels are encoded between clearings. (This was discovered by hacking my LZW decoder to show the number of symbols decoded since the previous clearing.) This behavior of frequently clearing the dictionary is sufficient to avoid the DCC bug that some GIF decoders have.
Program versions used: IrfanView 4.38 (), Adobe Photoshop CS5 Extended, OptiPNG 0.7.5 ().
Optimization algorithm example
Here is a small artificial example to illustrate the optimization technique. In the following table, the row represents the start block offset and the column represents the end block offset. For example, the table says it takes 20 bits to encode the input data range starting at block 3 and ending at the start of block 5.
| End | ||||||||
|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | ||
| Start | 0 | 1 | 10 | 30 | 40 | 50 | 65 | 70 |
| 1 | 1 | 15 | 25 | 30 | 50 | 55 | ||
| 2 | 1 | 15 | 25 | 30 | 60 | |||
| 3 | 1 | 15 | 20 | 35 | ||||
| 4 | 1 | 10 | 20 | |||||
| 5 | 1 | 10 | ||||||
We can use dynamic programming to distill this information into better information. The next table describes the minimum number of bits to encode the input data starting at block i and going to the end of the data, assuming that the dictionary can be cleared at various points during encoding. It also describes the number of blocks to encode starting at the current offset to achieve this minimum size, such that afterwards the dictionary is cleared and a new block would begin.
| Start offset (blocks) | 0 | 1 | 2 | 3 | 4 | 5 |
|---|---|---|---|---|---|---|
| Minimum encoded size | 60 | 50 | 40 | 30 | 20 | 10 |
| Num blocks to encode | 1 | 3 | 3 | 2 | 2 | 1 |
Based on these numbers, a final optimal encoding will split the input into these block ranges: [0,1), [1,4), [4,6). Or to state it compactly, the set of block boundaries will be {0, 1, 4, 6}. The encoded size will be 10 + 30 + 20, which is less than the size 70 we would get if we started at block 0 and encoded all the way to the end without clearing the dictionary (the monolithic encoding).
Note: In addition to controlling the block splitting / Clear code, there might be another way to optimize the LZW compression. The technique is called “flexible parsing” (as opposed to greedy longest match), and is described in various research papers. However, after I tried implementing it, my experiments (unpublished) suggest that applying FP noticeably increases the file size. This is probably because non-longest-matches cause duplicate dictionary entries to be added, which ultimately worsens the compression ratio.