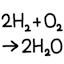 Chemical equation balancer (JavaScript)
Chemical equation balancer (JavaScript)
Program
Description
After you input an unbalanced chemical equation, this easy-to-use program calculates the coefficient of each reactant and product to achieve proper balance.
The core calculation algorithm is a slightly modified version of Gauss–Jordan elimination that operates using only integer coefficients (not the usual fractions).
This program was hand-written in JavaScript in the year , received minor feature updates and clarifications and refactorings throughout the years, and was ported to TypeScript in . The source TypeScript code and compiled JavaScript code are available for viewing. Because the program is entirely client-side JavaScript code, this web page can be saved and used offline.
Syntax guide
Error message guide
- Syntax error
Your input does not describe a proper chemical equation. Check each letter carefully, and follow the examples as a guide to the correct syntax.
- All-zero solution
The only mathematical solution to your equation has all coefficients set to zero, which is a trivial solution for every chemical equation. For example, C → N2 can only be satisfied by 0C → 0N2.
- Multiple independent solutions
There exist multiple solutions to your equation that are not simply multiples of each other. Your equation can be considered as two or more independent equations added together. For example, H + O → H2 + O2 has no unique solution because two solutions are 2H + 4O → H2 + 2O2 and 6H + 2O → 3H2 + O2, which are not multiples of each other. Furthermore, the equation can be separated as H → H2 and O → O2, each of which does have a unique solution.
- Arithmetic overflow
Your equation used numbers that are too big, or a term has an element that occurs too many times, or the internal calculation used numbers that are too big. I don’t expect this error to occur for real-world chemical formulas, only deliberately contrived ones. There is no workaround; the code would need to be rewritten to use bigints.
- Assertion error
The author/
programmer made a serious logic mistake. This error should not happen, but if it does please contact me.
Note: For simplicity of implementation, if the equation is successfully balanced but one or more terms have a negative coefficient, the program doesn’t consider this outcome to be an error condition. In this case, each term that has a negative coefficient should be put on the other side of the equation, and its new coefficient should be the absolute value of the negative coefficient.
Implementation details
Data representation
A raw chemical element is a string of letters that begins with an uppercase letter and is followed by any number of lowercase letters. The regular expression is
/[A-Z][a-z]*/. For example, these are elements: H, Na, Uuq. The exception is that e by itself represents an electron.An
ChemElemobject is a chemical element with a positive integer repetition count. For example: Fe, H2.A
Groupobject is a parenthesized list ofChemElemorGroupobjects, with a positive integer repetition count for the whole group. For example: (H2O)6, (C(OH)3)2.A
Termobject is a list ofChemElemorGroupobjects, with an integer electric charge for the whole term. For example: H3O+, S2−.An
Equationobject is a list ofTermobjects for the left side and a list ofTermobjects for the right side. For example: C + O2 → CO2.
Parsing the input
Your text input is parsed by a hand-written tokenizer and a recursive descent parser with one token of look-ahead. The parser takes a lot of code to implement and is ugly, but it is robust. The parsed result is your chemical equation in the internal object representation. In the code, this functionality is found in parseEquation(), parseTerm(), parseGroup(), parseElement(), parseCount(), and Tokenizer().
Setting up the matrix
The idea is to set up a system of linear equations to represent the balancing problem. Each term in the equation gets a variable. Each different element, and also electric charge, gets an equation. In the code, this functionality is found in buildMatrix(), Equation/, Term/.
For example, the equation H2 + O2 → H2O has 3 terms and 2 elements (H, O). We give a variable to represent the coefficient for each term, and we get aH2 + bO2 → cH2O. Now we make an equation for each unique element. For H, the equation balances only if 2a + 0b = 2c. In our matrix, we actually represent this equation as 2a + 0b − 2c = 0, using the row of integers [2, 0, −2]. For O, the equation is 0a + 2b = 1c, and we get the matrix row [0, 2, −1]. Even though none of the terms in this example are electrically charged, we always add an equation for electric charge anyway. In this case, the equation is 0a + 0b = 0c.
There is one more step in setting up the matrix. So far, all the equations form a homogeneous linear system. This means setting all the variables to zero is a solution, and each solution multiplied by any real number is also a solution. By convention in chemistry, we want the solution where all the coefficients are the smallest possible positive integers. So we add a (somewhat arbitrary) non-homogeneous equation stating that the first term should have a coefficient of 1, to break the symmetry. The matrix gains a column on the right, initially filled with zeros. Then the matrix gains a row of the form [1, 0, ..., 0, 1].
Solving the matrix
The standard Gauss–Jordan elimination algorithm is used to bring the matrix to reduced row echelon form, but with an important modification. My algorithm always works with integers (not fractions or floating-point numbers) and is exact. After each operation, each row in the matrix is put into simplified form, i.e. the GCD of all the numbers in the row is either
1 or 0. The final matrix is in quasi-RREF where the leading coefficients need not be 1, but all the zeros are the same as in RREF. The key idea that makes integer-only operation possible is that when eliminating, the two rows involved are brought to a suitable common multiple. For example, to use x = [3, 1, 4, 5] to eliminate the first column from y = [2, 7, 1, 8], we compute 3y − 2x = [0, 19, −5, 14]. In the code, this functionality is found in Matrix, Matrix.
Extracting the answer
If the chemical equation has n terms and there is a unique solution, then the solved matrix will have n non-zero leading coefficients. From the way the matrix was set up, the solution is normalized so that the first term has a coefficient of 1. But if this results in another term having a fractional coefficient, then all the coefficients are multiplied by the smallest positive integer so that all coefficients are integers. What actually happens in the code is that the least common multiple of all the leading coefficients is computed, and then the top left n × n of the matrix is made to become the LCM times the n × n identity matrix. In the code, this functionality is found in extractCoefficients().
Displaying the balanced equation
The balanced chemical equation with coefficients for the terms is rendered beautifully in HTML, with proper symbols, subscripts, and superscripts. In the code, this functionality is found in Equation/.
Exact syntax
To parse the formula, the string is first converted into a sequence of tokens, and then these tokens are parsed into a tree structure.
Tokens
These are the tokens and their definitions in regular expressions:
- Space:
/ +/(tokenized but filtered out) - Name:
/[A-Za-z][a-z]*|e/ - Number:
/[0-9]+/ - Punctuation:
/[+\-−^=()]/(each letter is a different token, and both - and − mean minus)
Grammar
The following context-free grammar (CFG) describes the set of syntactically correct chemical formulas:
- Equation (root) = Term (Plus Term)* Equal Term (Plus Term)*
- Term = (ChemElem | Group)+ (Caret Number? (Plus | Minus))?
- Group = LeftParen (ChemElem | Group)+ RightParen Number?
- ChemElem = Name Number?